Analysis
Ten Takes on DeepSeek - by Peter Wildeford - The Power Law
20250131 Schmidhuber tweet
Jürgen Schmidhuber @SchmidhuberAI
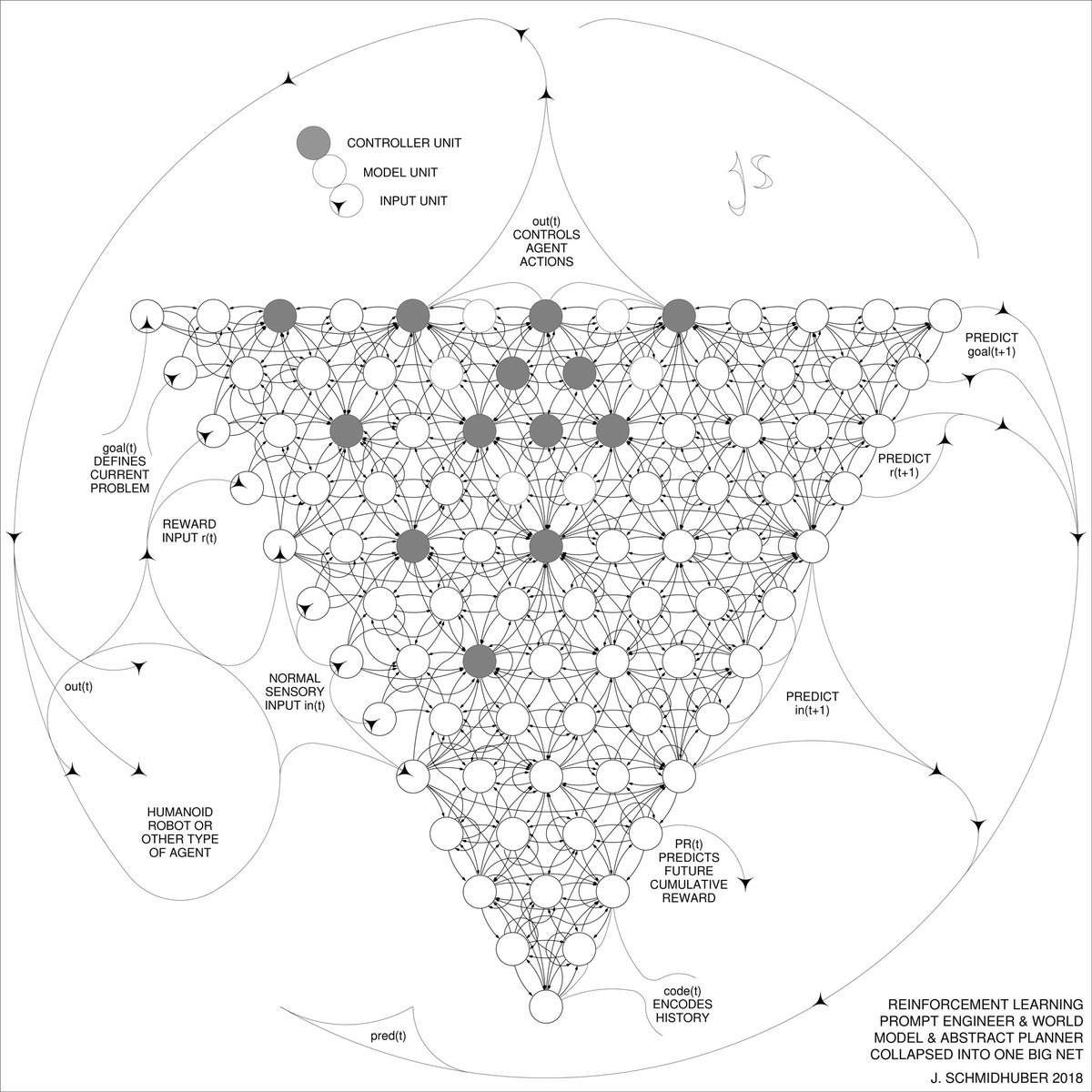
DeepSeek1 uses elements of the 2015 reinforcement learning prompt engineer2 and its 2018 refinement3 which collapses the RL machine and world model of2 into a single net through the neural net distillation procedure of 19914: a distilled chain of thought system.
REFERENCES (easy to find on the web):
-
#DeepSeekR1 (2025): Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2501.12948 ↩︎
-
J. Schmidhuber (JS, 2015). On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models. arXiv 1210.0118. Sec. 5.3 describes the reinforcement learning (RL) prompt engineer which learns to actively and iteratively query its model for abstract reasoning and planning and decision making. ↩︎ ↩︎ ↩︎ ↩︎
-
JS (2018). One Big Net For Everything. arXiv 1802.08864. See also US11853886B2. This paper collapses the reinforcement learner and the world model of2 (e.g., a foundation model) into a single network, using the neural network distillation procedure of 19914. Essentially what’s now called an RL “Chain of Thought” system, where subsequent improvements are continually distilled into a single net. See also 55. ↩︎ ↩︎
-
JS (1991). Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991. First working deep learner based on a deep recurrent neural net hierarchy (with different self-organising time scales), overcoming the vanishing gradient problem through unsupervised pre-training (the P in CHatGPT) and predictive coding. Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills - such approaches are now widely used. See also 66. ↩︎ ↩︎ ↩︎ ↩︎
-
JS (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990, introducing high-dimensional reward signals and the GAN principle). Contains summaries of 22, 33 above. ↩︎
-
JS (AI Blog, 2021). 30-year anniversary: First very deep learning with unsupervised pre-training (1991)4. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be distilled 4 into a single deep neural network. 1993: solving problems of depth >1000. ↩︎