Rust: Notes on memory management
Memory management and Rust’s data ownership model.
Rust guarantees memory-safety without the overhead of a garbage collector by implementing a unique data ownership model. Knowing at least some of the details of Rust’s data ownership model from the perspective of memory allocation will come in handy when writing and debugging Rust code.
Let’s dive in.
nb: This post is somewhat terse, intended to provide an outline of the essentials, leaving the details for further independent inquiry.
Virtual memory, stacked
Rust’s virtual memory isn’t wood and can’t be purchased, but these are and can.

Memory allocation: virtual mapped to RAM
Rust code is compiled into an executable binary prior to running as a process supported by the host operating system; the compiler takes the high level Rust code and translates it into CPU-executable instructions.
Running the binary spawns a process abstraction that includes a name, id, etc. Multiple processes run in parallel on the CPU. Each process will have memory allocated for it, and that allocation is initially done in virtual address space, not physical RAM. The kernel maps virtual addresses to RAM when the process (program) starts to use them.
Virtual memory (CPU) vs. physical memory (RAM).
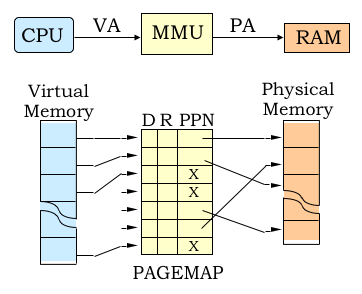
The memory stack initially constructed in a virtual address space consists of a continuous range of (virtual) memory addresses allocated to the process per its binary executable. The process ‘sees’ a continuous range of memory from zero up to the highest allocated value.
The executable format (eg ELF-64) sets the block segments in the virtual address space. The number of segments depends on the compiler, and specific blocks will depend on the program.
Block segments
The lowest address in the virtual address space will hold the text aka code segment that includes the CPU-executable, read-only instruction set. The instruction set is (CPU) architecture-dependent: the binary for x86-64 won’t work on ARM-64.
A data block is next and will hold initialized variables; this block is read/write.
Then, a bss block (‘block started by symbol’) holds uninitialized global variables.
Next, additional data - specifically, env vars, user input at execution, and arg count - will be mapped by the kernel to the highest end of the address range.
Importantly, there’s a gap between the bss and additional data blocks; this gap accommodates the stack and the heap, where ephemeral data is managed dynamically as the process runs.
The stack segment is allocated near the high end of the memory address range. A process can run across multiple threads; each thread will have its own stack segment.
Rust programs use an 8 MB stack for the main thread when run on 64-bit Linux systems. The stack size for additional Rust program threads defaults to 2 MB but can be specified as more or less than that.
A note on stack overflow:
- The main thread 8 MB is not allocated in memory by the compiler until the program uses it.
- The
stackgrows downwards, towards lower memory addresses. Within this main thread,fn main()receives an allocation, and subsequently called functions receive additional temporary allocations, effectively deallocated on function termination. - If the program thread exceeds its allocation (e.g., 8 MB for the main thread), the kernel terminates the program and produces a stack overflow error.
Heap memory, in contrast, isn’t per thread; in virtual address space, it starts after the bss (uninitialized global variables) block and grows upwards, toward the stack block.
Inspecting memory blocks
For Linux systems, to view memory block details, use cat /proc/PID/maps or open the /proc/PID/maps/ file in an editor.
For MacOS, vmmap --wide PID works but is slow, taking ~2 seconds per PID. Julia Evans wrote a faster version of vmmap in Rust.
Stack and heap addresses: potential overlap?
If you inspect the heap and stack addresses using the above tools, you’ll see that the highest heap address and lowest stack address are tens of TB apart. How is that possible if, say, the computer RAM is only 16 GB? Well, those aren’t physical memory addresses, right? And allowing for an oversized virtual address range makes the abstraction useful: ordered, purpose-specific blocks can be organized sparsely without any repercussions.
The addresses are allocated in a virtual continuous range and subsequently mapped to RAM. Those RAM addresses need not be contiguous, nor will the blocks necessarily be ordered as they were in virtual address space.
The memory address range and word size of a CPU depend on whether the CPU is 64-bit or 32-bit. For a 64-bit CPU, the word size is 8 B (the word size is nominally the same as the register size1). Since each bit can be 0 or 1, a 64 bit address covers values $ 0 \text{ to } 2^{64}-1 $; compare this to 32-bit systems, where the maximum value is $2^{32}-1$ and, thus, capable of representing only ~4 GB.
64-bit systems actually only use 48 bits for memory addressing up to ~281 TB: the lowest 47 bits for user space memory; the highest bit (~141 TB of virtual memory) is reserved for the program, for the kernel’s use.
The highest address in user space in hex is 0x7fffffffffff; you’re likely to see the stack at around that value in the memory map.
Stack memory
The stack memory is primarily used for executing the current function. Recall that it tops out at 8 MB and is allocated as it’s used, not in advance.
When executed, a function’s [parameters, local variables, return address] are placed on the stack. The total memory allocated for function execution is its stack frame.
As a concrete example (code below), let’s say we have a main function which calls a plus function using two local variables that are both i32. The stack frame for main will accommodate the variable names and values: a and b. Both are of type i32, which needs 4 B. The stack pointer will jump to the appropriate address to then allocate memory addresses for plus in its stack frame; here, memory is allocated for its two inputs and its return address, and the stack pointer is now at the end (bottom) of the plus frame.
fn main() {
let a = 1;
let b = plus(a, a);
}
fn plus(x: i32, y: i32) -> i32 {
x + y
}
When plus is executed within main, the value for b is received at b’s value address, and the stack pointer returns to the bottom of the main stack frame.
At this point, the plus frame is not deallocated, but will be overwritten by the stack frame of the next called function.
Allocating on the stack is fast! No system calls are required: the stack pointer is simply incremented and decremented.
Storing data on the stack comes with a few caveats:
- at compile time, a stack-allocated variable’s size must be known
- a reference to a function’s local variable can’t be returned as it will have been overwritten after the function returns, whereupon the function’s stack allocation is effectively deallocated
- in a garbage collected language, the compiler will handle this by allocating the referenced local variable to the heap
- in Rust, the heap assignment must be done explicitly
Heap memory
In Rust, a variable will be stored on the heap only if explicitly placed there.
This is accomplished by assigning the variable to a data structures whose headers (composed of data of known size) are stored on the stack while its data value is stored on the heap.
The header details depend on the data type, but always include a pointer which holds the address to the heap memory location of the data value.
The heap enables data-sharing via pointer copying, which can be done across threads as there’s only one heap (vs independent per-thread stacks).
Heap memory is usually managed by the program’s memory manager, which makes system calls to request more memory when required. In Linux, these calls are brk and sbrk. In Rust, the GlobalAlloc trait defines the functions that a heap allocator must provide. The compiler will insert those system calls automatically; they’re rarely inserted directly into the Rust code. Since system calls are relatively slow, additional heap memory will be requested in chunks (vs just the amount required for a single Box<T> variable or similar).
Unlike the stack, freed memory on the heap isn’t necessarily located at either ’end’ of the heap, and it may not be immediately returned to the OS. The program memory manager keeps track of freed heap memory ‘pages’ and can reallocate those without waiting for the OS or kernel.
The default heap-allocated data structure is Box<T>.
fn main() {
let boxed_result = get_heap_item();
}
fn get_heap_item() -> Box<String> {
let hv = Box::new("boxed string");
hv
}
The stack will have an allocation for boxed_result in the fn main() frame, and an allocation for hv in the fn get_heap_item() frame. The hv allocation on the stack will consist of a pointer to the heap memory address of the data value. **In 64-bit OSs, pointers receive an 8 B memory allocation.
Once fn get_heap_item() returns a pointer to the main() scope, boxed_result becomes the owner of the pointer and the original owner (hv) goes out of scope and is no longer accessible.
The data value of a boxed variable can be referenced by using the * operator to dereference the variable.
Memory allocations of Rust data types, traits, functions, and closures
Stack-allocated
iNoruN: N/8 Bisizeorusize: machine-word size (64-bit: 8 B)char: 4 B (these are unicode characters)tuple: ordered, fixed-size collection of stack-allocated values, can be of different typesarray: ordered, fixed-size collection of stack-allocated values, all of the same typereference: machine-word sized, can be ref to a variable (stored on the stack OR the heap), ref to another refmutable reference: same asreferencebut with additional restrictions imposed by the compilerslice reference: a fat pointer = pointer + length; the data referenced by the pointer can be either on the stack or the heapdynamically sized type reference: same asslice referencetrait object: nb: different fromtraitstring literal: a string literal stored directly as a variable, it will be a reference to the string slice data: aslice reference(yes, a fat pointer)- nb! the string data is NOT stored in heap memory; it’s stored directly in the compiled binary (read-only) and has a static lifetime, meaning it is never deallocated
range of string literal:string slice==slice reference
// this will error because size is not known at compile time
let s1: String = String::from("hello");
let s: str = s1[1..3];
- in the above,
swould be a slice reference, with a fat pointer that holds the address of the first element of theStringand the size ofs; but! Rust doesn’t allow this as written above because the the size won’t be known at compile time, so a reference must be used:
let s: &str = &s[1..3];
- it might be useful to think of a ‘variable’ as something that includes a data value and a ‘reference’ as something that never includes a value, only a pointer/address (and, possibly, a length)
Heap-allocated
tuple: ordered collection of values with at least one heap-allocated type, can be of different typesarray: ordered collection of values with heap-allocated data typevec: stack (metadata: name, len, cap, pointer to value on heap) + heap (data value), where the data value is a variable-length array of values with a single data typedynamically sized types:slice,string slice,traitString: same asvecexcept its values are guaranteed to be UTF-8 encoded
Struct data types
Rust has 3 different struct types:
- with named fields:
struct Data { nums: Vec<usize>, dimension: (usize, usize) } - tuple-like:
struct Data(Vec<usize>) - unit-like:
struct Data
Unit-like doesn’t contain any data so the compiler doesn’t allocate any memory (stack nor heap).
Tuple-like and with named fields are allocated memory similarly to tuple types, allocating to the stack or heap depending on the field data types.
Enum data type
Rust supports several syntaxes for enums; these enumerate fixed variants. In memory, each variant of an enum has the same size.
This example is a C-styled enum. In memory, the named fields are stored as integer tags, starting from 0 if no values are assigned.
enum HTTPStatus {
Ok,
NotFound,
}
Above, HTTPStatus::Ok is 0 and HTTPStatus::NotFound is 1. The highest value, 1, can be stored in 1 bit, so the encoding of the enum values will be 1 B (the minimum memory alignment).
Similarly, the enum could store integer values for variants:
enum HTTPStatus {
Ok = 200,
NotFound = 404,
}
Above, the highest value is 404, requiring at least 10 bits, so 2 B.
Another valid enum is:
enum Data {
Empty,
Number(i32),
Array(Vec<i32>),
}
To figure out memory allocations for the variants, identify the variant that requires the most memory.
Array has stack memory allocated for its integer tag (here, “2”, which requires 2 bits, or 1 B) plus 3 machine-word sized allocations (pointer, len, cap) plus padding. On a 64-bit OS, this variant takes 32 B. When the variant receives data, the requisite memory will be allocated on the heap.
Number has stack memory allocated for its integer tag (“1”) and an i32 value. It’ll be padded to 32 B.
Empty has only its integer tag (“0”) and will be padded to 32 B.
Reducing the size of the largest enum variant is desirable. In the example above, instead of storing a pointer to a Vec<i32>, storing a pointer to a Box<Vec<i32>> would reduce each enum variant memory allocation by half.
Here’s why: The stack allocation for the boxed variant includes the enum integer tag plus the pointer to the heap memory address of the Vec<i32> header2. In contrast, the stack allocation for the vector header - in addition to the tag plus the pointer - must also accommodate the values of len and cap. The enum variant allocations are of the same size; thus, replacing the vector variant with a boxed variant reduces the storage required for each enum variant by the len and cap memory requirements.
A very common enum is Option:
pub enum Option<T> {
None,
Some(T),
}
The Option enum is used to represent values that can be null or empty, so their representation is unambiguous (i.e., not 0, null, etc.).
For example, say variable intended to hold an i32 is declared for allocation on the heap as Option<Box<i32>>. In other languages with pointers, prior to allocating data, the variable would be represented by a ’null’ or ’nil’ pointer. Rust’s Option reinforces safety by circumventing the use of null pointers, which can cause issues if they should be dereferenced.
In the Option enum, the None value only stores the integer tag. The Some value stores the integer tag plus an allocation according to its data type. In the case of a Box<i32> type, one machine word is allocated to store the pointer to the Box data allocated on the heap.
nb: The Rust compiler can do some optimization for Option where the Some type is a Box or other ‘smart’ pointer type. In that case, the pointer cannot be of value ‘0’ (the None integer tag value), so Some’s integer tag can be omitted, reducing the variant memory allocation to the machine-word size for the pointer alone.
Copy vs Move
For primitives such as integers, when the variable is assigned to a new variable, the new variable gets a bit-by-bit copy of the value. In other words, a duplicate of the value becomes assigned to the new variable name. The assignment does not persist a link between the two variables.
fn main () {
let num: i32 = 5;
let num_copy = num;
// num_copy holds a copy of num's value, so num and num_copy may be used independently, and each variable will exist in its respective scope
let double = two_times(num_copy);
// num_copy has been consumed and is no longer in scope, but num is still accessible
println!("num is {} and double is {}, but num_copy is no longer available in this scope", num, double);
// so far, so good - but...
println!("num_copy no longer accessible, this should error: {num_copy}");
}
fn two_times(n: i32) -> i32 {
n * 2
}
If the same applied to variables on the heap (with just their header data on the stack), those distinct variables’ pointers would refer to the same location on the heap. This would introduce ambiguity about responsibility for the referenced heap memory - a situation which Rust was expressly designed to avoid, so the operation in this case is not copy but move: the ownership of the data at a heap memory address changes (ie, is moved) to the new variable.
A simple example: a vector of String elements is assigned a variable v, and v subsequently assigned to v2 results in the vector ownership passing from v to v2, and v no longer being in scope.
To duplicate the variable, it may be cloned instead, as let v2 = v.clone(). If not cloned, Rust automatically moves ownership of the heap allocated memory to the new variable v2, after which v can no longer be referenced. The heap memory is deallocated only when v2 goes out of scope.
Shared ownership via reference counting
What if multiple owners of the same immutable value are required? The value can be wrapped in an Rc smart pointer which counts references. The Rc variable can be cloned. Cloning an Rc variable increments the reference count; likewise, the reference count is decremented when the cloned variable goes out of scope. Once the reference count decrements to 0, the value’s memory allocation on the heap will be deallocated.
nb: Rc types can only wrap immutable variables. Interior mutability can be used to get around this limitation.
Send and Sync marker traits
From the Rust docs: “Some types allow you to have multiple aliases of a location in memory while mutating it. Unless these types use synchronization to manage this access, they are absolutely not thread-safe. Rust captures this through the Send and Sync traits.”
If a variable is of type Send, its value can be transferred to a different thread; if of type Sync, multiple threads can share the value by using shared references.
nb: T is Sync iff &T is Send; also, Rc isn’t Send or Sync since the reference count is shared, so is unsynchronized.
To share immutable data across threads with a reference counter, use Arc which is an Rc with reference count done by atomic operations; these are safe to do from multiple threads. (Arc = “atomically reference counted” pointer.) Keep in mind that there’s a (small) additional cost for atomic operations, so use Rc unless Arc is required.
To share mutable data via reference counter, use an Arc that wraps a mutex with the variable.
Trait object
A trait is, essentially, a table (vtable) with pointers to all the functions required for the trait. The table is generated once at compile time and shared among the program’s trait objects.
A trait object is represented by a fat pointer consisting of two pointers: one pointer to the original data type, and one pointer to the trait table which enables the data type to implement the trait.
To assign a trait object, assign a data type that implements the trait (in this case, the Rust standard library implements the Write trait for a Vec type):
use std::io::Write;
let mut buffer: Vec<u8> = vec![];
let w: &mut dyn Write = &mut buffer;
…or, use a data type that implements the trait as a parameter of a function that accepts a trait object:
use std::io::Write;
fn main() {
let mut buffer: Vec<u8> = vec![];
writer(&mut buffer);
}
fn writer(&mut dyn Write) {
// ...
}
In the above examples, Rust converted regular references to trait objects.
Rust can do the same for types with smart pointers, like Box and Rc:
use std::io::Write;
let mut buffer: Vec<u8> = vec![];
let mut w: Box<dyn Write> = Box::new(buffer);
use std::rc::Rc;
let mut w: Rc<dyn Write> = Rc::new(buffer);
A Box of dyn Write means a value that owns a writer in the heap.
When a reference is assigned to a trait object, Rust always knows the reference’s ’true’ type. In the simple first case above, that type is Vec<u8>, so the trait object consists of a pointer to the Vec<u8> and a pointer to the vtable.
Functions
The stack-allocated memory for a function consists of a pointer (one machine-word in size) whose value is the memory address of the function’s machine code in the appropriate segment of memory (code segment).
Closures
In Rust, closures don’t have a concrete type. They are constructed as trait objects, with one of three traits: Fn, FnOnce, FnMut.
Closures can access the data of their containing functions.
For a closure that implements the FnOnce trait, the closure will consume the data and its self parameter. In this case, the in-memory struct representing the closure consists of a copy of the captured data from the enclosing function; once captured, ownership is transferred to the closure and the original data deallocated from the enclosing function. The closure function takes a reference to self so cannot be called more than once. Its data (copy) is deallocated once the closure terminates.
An FnMut closure may mutate data from the containing function. In this case, the in-memory struct that represents the closure will have a mutable reference to any variable it uses from the containing function. The closure function takes a mutable reference to self and can be used multiple times. This closure must be called as mutable; this is done at its assignment: eg,
let mut i: i32 = 0;
let mut f = || { i += 1 };
f();
f();
println!("{}", i); // 2
A Fn closure uses but does not mutate values it uses from its containing scope. In this case, the memory structure is just a pointer reference to the value. The closure can be called any number of times and the variable in which the closure is stored doesn’t have to be mutable. An issue may arise: the reference might be to a value on the stack, and that frame may be deallocated. Rust won’t allow this, so the ownership of the data value must be reassigned to the closure via the move keyword. Then, the struct doesn’t contain the pointer to the value but the value itself.
Lifetimes
This post started out as an exposé of the literal mapping of Rust code to (virtual) memory. Rust lifetimes are qualifiers layered on top of that, so - squinting - could be considered out of scope. Or in. An argument could be made that addressing Rust lifetimes is an essential component of managing memory appropriately, so - staying true to the title of this post - its inclusion is warranted. TBD!
Async functions
Life of an Async fn in Rust: RustFest Barcelona 2019 - Tyler Mandry
References
- Rust docs: Understanding ownership
- Visualizing memory layout of Rust’s data types
- Rust: Memory management
-
For a discussion about how this isn’t necessarily true, see: https://stackoverflow.com/questions/77029456/what-does-word-size-mean-with-greater-size-registers. While fascinating, those further details have no impact on Rust memory management so long as the register size is at least as big as the word size, which it must - by definition - be. ↩︎
-
The vector data value will also be on the heap, at the address stored in the header pointer. ↩︎